

A team at Politecnico di Milano has demonstrated an analog in-memory computing chip that eliminates the data movement at the root of modern AI’s energy problem.
MILAN — Researchers at Politecnico di Milano have built a chip that performs calculations directly inside memory rather than shuttling data to a separate processor, achieving up to 5,000 times lower energy consumption for certain AI tasks while matching the accuracy of conventional digital systems.
The chip, described in Nature Electronics in January 2026, targets what computer scientists call the von Neumann bottleneck: the energy cost of moving data repeatedly between a processor and memory during computation.
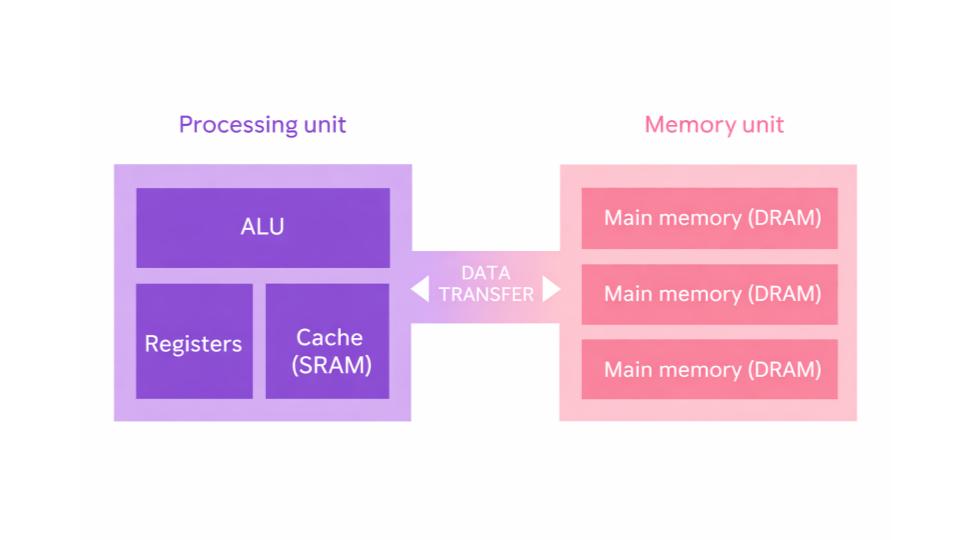
In modern AI hardware, that data movement accounts for a substantial share of total power consumption. The Milan design eliminates it entirely.
“The integrated chip demonstrates the feasibility on an industrial scale of a revolutionary concept such as analogue computation in memory,” said Professor Daniele Ielmini, lead researcher and a member of Politecnico di Milano’s Department of Electronics, Information, and Bioengineering. His team is already working on adapting the chip for real-world AI applications.
How it works
The chip uses two 64-by-64 grids of programmable memory cells whose electrical resistance values encode the numbers being processed. When an electrical signal passes through the grid, the physics of the circuit performs matrix multiplication in a single step, with no data sent to an external processor. The result emerges directly from the hardware.
This is an analog approach, exploiting continuous physical properties of electronics rather than the discrete ones and zeros of digital computing. Analog computation is more energy-efficient for certain problem classes but has historically struggled with precision. Small errors introduced by manufacturing variation or component drift compound over time, making results unreliable.
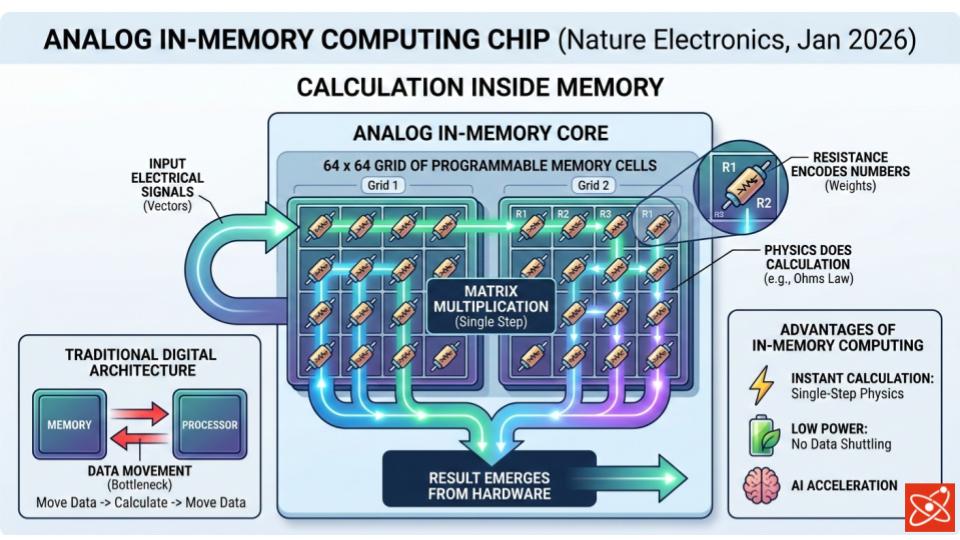
The Milan team addressed this with a closed-loop architecture that continuously monitors the chip’s output and feeds corrections back into the computation in real time. The self-correcting design brings precision to levels comparable with digital systems, resolving the core accuracy problem that has limited analog in-memory computing for years.
The scale of the efficiency gain
The 5,000-fold efficiency figure applies to specific tasks and represents a best-case outcome rather than an average. The gap is real nonetheless, and stems directly from what the design eliminates. In a conventional chip, data travels repeatedly between memory and processor during computation, burning energy with each transfer. In the Milan chip, the memory cells are the processor. The energy overhead of data movement drops to zero.
AI inference, the process of running an already-trained model to generate a response, occurs billions of times daily across global data centers. It represents a fast-growing share of worldwide electricity consumption. Hardware that cuts inference energy by a significant fraction of that factor has implications beyond laboratory performance benchmarks.
The chip was fabricated in standard 90-nanometer CMOS technology, the kind of industrial process that chip foundries worldwide already operate. That is a deliberate choice: the design is intended for realistic manufacturing rather than specialized cleanroom conditions.
Scope and next steps
The device is a proof of concept. The memory arrays are relatively small and the demonstrated applications are specific, focused on inverse matrix-vector problems that appear frequently in AI inference, wireless communications, scientific simulation, and control systems.
Scaling the arrays, integrating them into full AI accelerators, and adapting the closed-loop correction system for more complex models represents the work ahead. Ielmini’s team said it is already pursuing those applications.
The chip demonstrates that the precision problem long associated with analog in-memory computing can be solved without sacrificing efficiency. The von Neumann bottleneck is an engineering convention, not a physical constraint, and the Milan result shows it can be designed around.
Source: Mannocci, P. et al. “A fully integrated analogue closed-loop in-memory computing accelerator based on static random-access memory.” Nature Electronics, January 2026. DOI: 10.1038/s41928-025-01549-1. Quotes from Politecnico di Milano press release via EurekAlert.

Ray Jackson holds a BSc in Electrical Engineering from the University of Manitoba and a PhD in Physics from Carleton University. His reporting interests include Current and Future Technologies, Engineering and Artificial Intelligence.